
Choice Modeling in Pharmaceutical Marketing: A Precise Tool, Imprecisely Applied
Choice modeling has been the de facto tool for demand estimation in pharma for decades. Ask a brand team how they sized the opportunity for a new product, evaluated a line extension, or gamed out the impact of generic entry, and there is a good chance a choice model was somewhere in the process.
That familiarity is, in some ways, the problem. A methodology that is well understood can also become one that is applied on autopilot — commissioned because it is the expected next step rather than because the team has thought carefully about whether it is the right tool, whether the design is adequate, and whether the scenarios being tested are the ones that actually matter.
Choice modeling is only as good as the thinking that goes into it. The core output — a share estimate under a defined set of market conditions — is genuinely useful. But that usefulness depends entirely on the rigor of the design, the realism of the scenarios, and an honest understanding of what the methodology can and cannot do.
This article is an attempt to be precise about all three. I first wrote on this topic in 2008. The methodology has not changed much since then, and neither, if I am honest, have my views on it — but I think they are more precisely stated now than they were. The one exception is the multi-stakeholder architecture, where my thinking has genuinely evolved, and where I suspect the field has sometimes added complexity without a proportionate gain in usefulness.
The logic of trade-off measurement
Choice and conjoint models belong to a family of trade-off methods. The underlying premise is that the best way to understand how decision makers value a product attribute is not to ask them directly — direct importance ratings are notoriously unreliable — but to observe how they trade off attributes against one another when forced to make choices.
The mechanics work as follows. A drug in development is described by its key attributes: efficacy, side effect profile, dosing regimen, and so on. Rather than asking physicians to rate the importance of each attribute, researchers construct a series of product profiles — each a specific combination of attribute levels — and ask physicians to make choices among them. An experimental design algorithm determines which combinations to test. The result is a utility function that links product characteristics to prescribing behavior.
The critical distinction between traditional conjoint and choice modeling lies in the respondent task. In conjoint, respondents rate or rank profiles in isolation. The researcher then makes an inferential leap: that a higher-rated profile will actually be prescribed more.
Choice modeling eliminates that leap by placing the target product in its competitive context — alongside the alternatives a physician would actually consider — and asking for an allocation or a choice. The share estimates that emerge from a well-designed choice model are therefore more directly tied to the decision environment physicians face in practice.
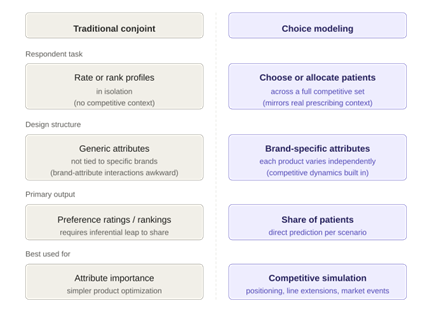
Figure 1: How conjoint and choice models differ in task design and output
A second structural difference is in the experimental design. Traditional conjoint designs use generic attributes, not tied to specific brands. This makes it awkward to model competitive dynamics, because the interaction between a product’s attributes and the competitive alternatives is exactly what drives real-world prescribing. Choice modeling designs assign attributes to specific products or brands, so the competitive context is built in.
From product profiles to positioning
The standard application of choice modeling is product profile optimization: finding the combination of efficacy, tolerability, dosing, and other attributes that maximizes patient share relative to the competitive set. The output is concrete — a share estimate for each profile — which allows teams to prioritize development decisions with real consequences attached.
Positioning research is a natural extension of this. The goal is to identify not just what the product is, but how to communicate it: which platform (mechanism of action, speed of onset, first-in-class status) and which supporting messages will drive the greatest uptake.
The conventional approach to positioning research — sequential monadic exposure followed by an association exercise — is structurally incapable of answering this question. It tells you which platform respondents prefer in the abstract, but it cannot tell you whether any of them will actually change prescribing behavior in response. It is also impossible to know, from such an exercise, whether the winning platform is genuinely strong or merely the least bad option.
The choice modeling framework treats positioning platforms as design variables in the same way that product attributes are design variables. Different platforms are combined with different sets of supporting messages to create complete positioning stimuli — something closer to what will eventually appear in a detail or a journal ad — and respondents allocate patients across all available treatments under each.
The output is a share estimate by positioning strategy, not a preference rating. This creates a direct link between the messaging decision and its expected market impact.
Modeling changes in the competitive environment
One of the more powerful uses of choice modeling is in anticipating competitive dynamics: how will the market restructure when a new entrant arrives, when an existing product gains a new indication, or when a competitor loses patent protection?
The brand-specific attribute structure of choice model designs makes this feasible. Each new product or event is incorporated as an independent design variable with its own set of attributes. Products are varied independently across the design, which means the model captures how physicians trade off each new entrant against every other option — new and existing — rather than treating the competitive set as a fixed backdrop.
The result is that the model can be used to simulate a range of market scenarios: only the first mover launches; both products launch simultaneously; a third entrant appears six months later. Each scenario yields a specific share estimate, for every product in the competitive set.
Line extension decisions are a particularly common application. The fundamental business question is whether the extension will grow the franchise or cannibalize it — and if it cannibalizes, from where does it draw its volume?
A well-specified choice model answers both. Because it tracks patient allocation across all products simultaneously, it produces not just a share estimate for the extension but a decomposition of its source of volume: how much comes from the parent brand, how much from each competitor. This is exactly the information a brand team needs to assess whether the extension creates net value or merely redistributes existing patients within the franchise.
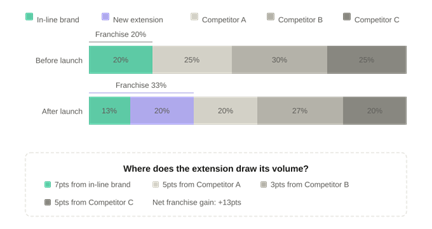
Figure 2: Postlaunch share shifts and source of volume — where does the extension draw its patients?
Market-level events: generics, formulary, and beyond
Some of the most consequential events a brand faces have less to do with product attributes than with market structure: the arrival of generics, changes in formulary coverage, shifts in patient out-of-pocket cost, or a switch from prescription to OTC status.
These events are hard to model with most research tools because their effects move through multiple decision makers in sequence. The solution is to treat each stakeholder as a separate model with its own respondent sample, connected by linkage variables that carry the output of one model into the inputs of the next.
The architecture is a cascade, not a feedback loop. The payer model comes first. Its inputs are the contracting variables — WAC, rebate, net price — along with a small number of clinical attributes relevant to formulary committee decisions. Its output is an access probability: the likelihood that the product achieves a given formulary tier under a given contracting scenario.
Those access probabilities then feed into the physician model and the patient model as separate linkage variables. For physicians, the relevant inputs are formulary tier and any associated restrictions — prior authorization requirements, step edits, quantity limits. For patients, the relevant input is the out-of-pocket cost implied by the tier.
The physician model produces prescribing probabilities, which enter the patient model as a further linkage variable: the likelihood that an HCP recommends this treatment. Patient behavior — whether they fill, persist, or switch — is then estimated as a function of both the HCP recommendation and the out-of-pocket cost.
The direction of influence runs one way throughout. This is a deliberate simplification, and in most markets it is the right one. Bidirectional feedback between models is technically possible but adds complexity without a proportionate gain in predictive accuracy. The exception is patient pull — cases where patients actively request a specific treatment, which can in turn influence physician prescribing. This dynamic is worth modeling when direct-to-consumer advertising is a significant factor, but it is the exception rather than the rule.
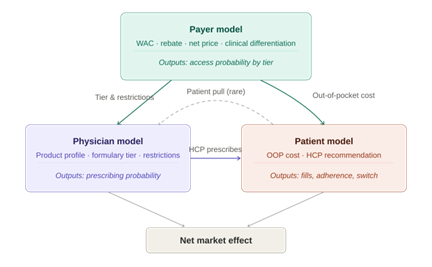
Figure 3: The integrated choice model — a one-directional cascade from payer to physician to patient
The goal is a bottom-line number, not a directional signal. Knowing that a new competitor “will reduce share” is not useful. Knowing by how much, and from whom, is.
Where the methodology has real limits
None of the above should be read as a claim that choice modeling answers every question. It does not, and overstating what it can do is one of the more common ways to undermine confidence in the methodology after the fact.
Choice modeling is fundamentally a survey-based tool. Its estimates of share are based on stated preferences in a structured task, not on observed market behavior. Physicians and patients behave differently under real economic constraints, real time pressure, and real uncertainty than they do in a carefully constructed survey.
This does not invalidate the methodology — all forecasting methods involve simplification — but it means that the estimates should be treated as directional guidance, not precise predictions.
The quality of the output is directly determined by the quality of the design. Poorly specified attribute levels, unrealistic competitive sets, tasks that overwhelm respondents, or experimental designs that confound the estimates will all yield results that look plausible but are structurally wrong.
There is no post-hoc correction for a flawed design. By the time the data are in hand, the damage is done. This is why the design phase is not a technical formality but the most consequential part of the entire project.
There is also a category of questions for which choice modeling is simply not the right tool. If the objective is to understand why physicians behave as they do — what beliefs, misconceptions, or emotional associations are driving their decisions — a choice model will not tell you. It will tell you what they choose; it will not tell you why.
Qualitative methods, belief-elicitation surveys, and other tools are better suited to that purpose. The appropriate response to those objectives is not to force-fit a choice model, but to design research that actually matches the question.
The bottom line
Choice modeling is most valuable when there are concrete decisions to be made, multiple possible outcomes to evaluate, and a need to quantify the effect of those outcomes on prescribing behavior. Positioning optimization, competitive simulation, line extension assessment, and market event modeling all meet that description.
The methodology is genuinely well-suited to these problems in a way that few other quantitative tools are. But its value is not intrinsic to the methodology. It depends on the rigor of the design, the realism of the scenarios tested, the care with which the results are interpreted, and the willingness of the team to engage with the assumptions the model requires.
A choice model that has been designed carelessly, run on an unrepresentative sample, or interpreted without attention to its limitations is not just unhelpful — it can actively mislead.
The goal of marketing research has always been to reduce uncertainty well enough to support better decisions. Choice modeling, when it is done well, does that as effectively as any quantitative method currently available. It does not eliminate the need for judgment, and it does not produce certainty.
What it produces, in the right hands, is clarity — which is usually what the decision maker actually needs.